
Search for answers or browse our knowledge base.
Supporting Semantic Search
Supporting Semantic Search
Sean Fitts
8 June 2023
Last revised: August 2023
Revision: 0.60
Introduction
As we explore how to enable the use of Generative AI (Gen AI) in Vantiq applications, one capability that we’ve identified is Semantic Search. The goal of semantic search is to query a body of data using not just simple matching heuristics (aka “lexical search), but by determining the intent and contextual meaning of the search query and finding matching concepts in the search target. Combining searches based on semantic similarity with Gen AI enables a very powerful “conversational” search style which is often referred to as “Chat Your Data”.
In a Vantiq context, we see use cases involving users querying a knowledge base and combining their own knowledge with the real time state of the system. For example, a technician dispatched to repair a generator might use semantic search over the repair manual and technical specifications to determine how best to address an issue, given the generator’s current operating parameters. We also see applicability to our own product to help developers search our documentation and tutorials for help in building their applications.
In this document we propose an approach for adding a “semantic search” capability to the Vantiq platform. This is not the only “LLM enabled” capability that we plan to add, but the discussion of any others will be addressed in separate documents (in the interests of keeping each one relatively focused).
Semantic Search Architecture
Before we get into the specifics of how we propose to enable semantic search within Vantiq, it will be useful to understand a general semantic search architecture (others are of course possible, but this represents a typical architecture using currently available technologies).
Vectors and embeddings
The basis of semantic search is the fact that we can analyze a search target (such as a collection of documents) and use a neural network to “encode” it such that we can match elements based on their semantic similarity. The encoded results are known as “embeddings” and they consist of a vector of floating-point numbers (the size of this vector varies depending on the neural network used to perform the encoding). The encoding works such that 2 elements whose vectors are “near” each other (based on a specific measurement such as the cosine of the angle between the vectors) are also close to each other in meaning. By applying this encoding to both the query and to the potential answers, we have a way to compare them semantically as shown below:
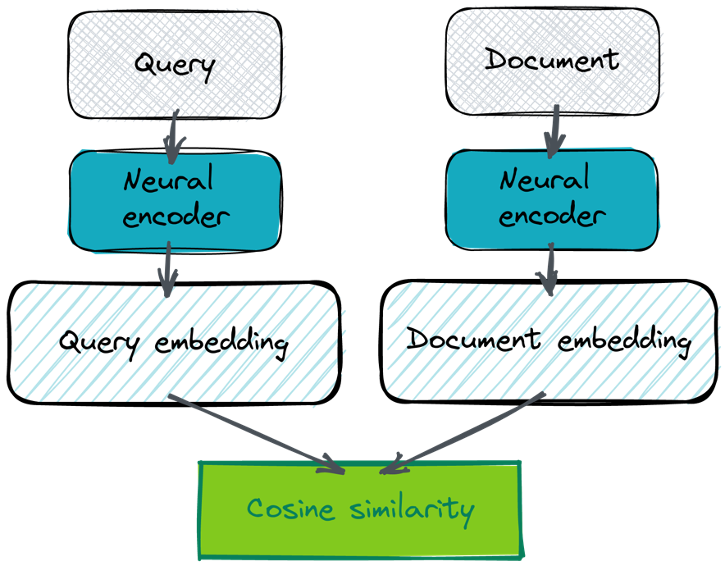
It is important to know that different “encoders” (which are themselves a type of large language model), produce embeddings that must be compared in specific ways. For instance, the above example uses the cosine of the angle between the 2 vectors (aka cosine similarity). This is something you must just “know” based on the description of the model (there is nothing in the embedding vector which tells you this). Additionally, you must use the same model to create both the query and document embedding. Otherwise, they likely won’t be comparable.
Efficiently storing and searching embeddings
Of course, we don’t want to have to continuously recreate embeddings from the documents we are searching, and we don’t want to have to perform similarity comparisons on each vector one at a time. We need a way to persistently store the embeddings once they have been created and to search those embeddings as shown above. This is the role of a Vector Database (Vector DB).
A Vector DB allows us to store the embeddings and any associated “metadata” (such as a reference to the document or the text that was encoded) and perform efficient searches using a target vector (here the “query embedding”) and optionally a filter based on the metadata values. The first step is to create embeddings for all the documents we wish to search and store those in the Vector DB as shown here:
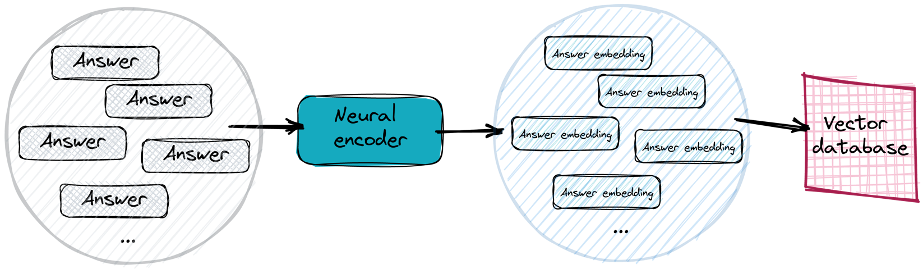
Once that’s done, we can then take any queries, encode them to create an embedding and search the Vector DB to find the potential answers to our question:

Leveraging Generative AI models
Prior to the introduction of generative LLMs such as GPT, the process would have stopped there. We could display the search results to the user, and they could then access the original source material and read through it to (hopefully) answer their question. This is better than a purely lexical search, but still relies on the user’s ability to read and understand the source material. Gen AI enables us to go one step further and synthesize a more direct answer that incorporates the knowledge from candidate answers and leverages the general reasoning capabilities of the generative LLMs.
To accomplish this, we take the results of the vector similarity search (the candidate answers or facts) and format them, along with the original question, into a “prompt” which is sent to a generative LLM. The LLM is then able to formulate a response based on its general knowledge and the specific facts that it has been presented. The user is presented with this result (along with references to the source material used). It turns out that in most cases the response generated by the LLM is more useful and easier to understand than the underlying source material. This sequence is depicted here (Qdrant is a Vector DB vendor and Langchain is an LLM application framework, more on both later in this document):
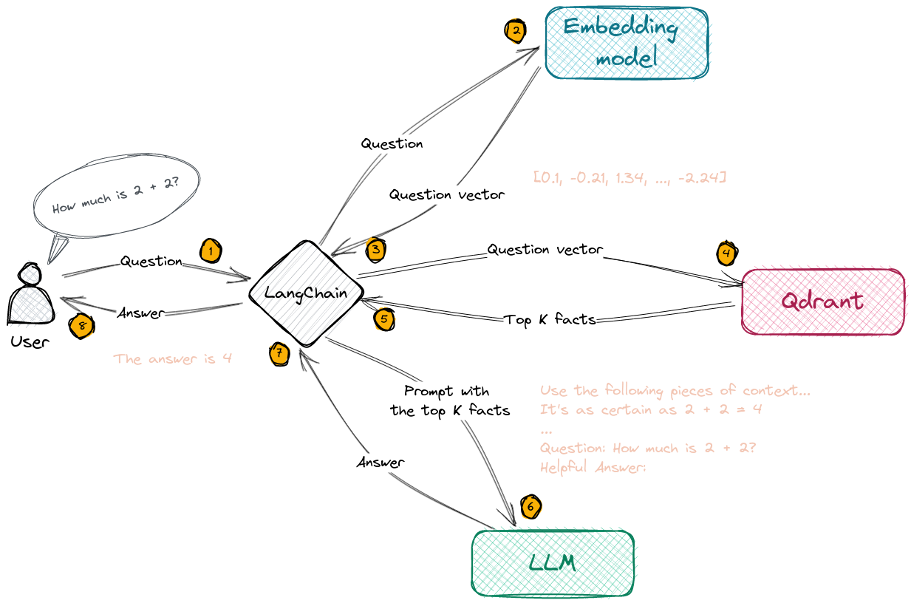
We can also allow the user to ask “follow up” questions to help clarify any aspects of the response that were unclear or to explore a related topic based on that initial response. This is accomplished by performing the same process using the new question (to obtain a new set of candidate answers) and presenting both the original interaction (or a summary of it) and the new question and facts to the LLM.
While this sounds great, it is worth noting that one limitation of the current LLMs is that too much information can be a bad thing. All the LLMs have hard limits on the amount of data they can accept measured in something called “tokens” (there are roughly 2-3 tokens per word). In addition, the more information the LLM receives the more likely it is to infer semantic connections that don’t exist. This can lead to it fabricating responses that simply are not true (a phenomenon known as “hallucinating ”). For example, when trying to answer a question based on the contents of a document, it is often better (or even necessary) to provide the LLM with only specific sections of the document, rather than the whole thing. This is addressed when we create the embeddings that are loaded into the Vector DB. Rather than creating an embedding for an entire document, we instead divide the document up into “chunks” (often overlapping) and create embeddings for these. These “chunks” are then sent to the LLM resulting in both reduced token sizes and a more focused context (which typically yields better results).
Design
Managing Embeddings via a Semantic Index
As outlined above, to enable semantic search, we first need a way to create a database of embeddings for the documents we intend to search. We call this a “semantic index”. We want to allow developers to create multiple such indexes, one for each related collection of documents. Once created, developers should be able to manage the contents of the index (add/remove documents) and use the index to perform semantic searches.
To support these capabilities, we propose the addition of the Semantic Index (semanticindexes) resource. This resource encapsulates the creation and management of a related set of document embeddings, their storage in a Vector DB, and the ability to perform similarity searches against them. To create a semantic index, the user must provide a unique identifier (aka name) and a reference to the LLM which will be used to generate the embeddings. This LLM instance must already exist and be an “embedding” model.
Once an index is created, the next step is to load it with one or more documents. Documents can be loaded into the index in one of 3 ways:
- Using a reference to a Vantiq document resource.
- Using a URI from which the document’s contents can be read.
- By directly uploading the contents of the document to be indexed.
In all 3 cases, the user can provide additional “metadata” (in the form of JSON documents) which will be associated with the embeddings in the index.
Semantic Index Resource
The semanticindexes resource is a Vantiq system resource with the following properties:
- name: String – a unique identifier for the resource instances which must conform to standard Vantiq resource name constraints.
- embeddingModel: String – the name of the LLM used to produce the embeddings managed by the index. The value is immutable once set.
- description: String – an optional, human readable description of the index.
- defaultQALLM: String – the optional name of a generative LLM used to synthesize answers to submitted questions. Setting this value allows for the use of the io.vantiq.ai.SemanticSearch.askQuestion procedure without the need to establish a Q&A session.
- entries: SemanticIndexEntry Array – a read-only property which lists the documents which are part of the index. The entries in the array have the following properties:
-
-
-
- id: String – a unique identifier for the entry.
- status: String – the status of the entry. Possible values are pending, loading, loaded, error.
- fromContent: Boolean – optional value that will be “true” when the entry was loaded from embedded content.
- uri: String – optional value will be set when the content was loaded via a URI (note that in other cases the URI may be set in the metadata).
- resource: ResourceReference – optional value that will be set when the content was loaded from a Vantiq resource.
- filename: String – optional value that will be set when the content was uploaded from a source file.
- error: String – the error message stored if there is an error loading the entry into the index. Will only be set if the status is error.
- metadata: Object – a collection of key/value pairs associated with the document. Some common keys are:
-
-
-
-
- uri: String – a URI that can be used to access the document. Useful when providing citations to the user.
-
-
-
-
The resource supports all the standard CRUD operations. It also supports the following additional operations.
Add Entries
Specifies one or more documents to be loaded into the index. The request requires an array of Objects, the contents of which depend on how the document contents will be provided. All the options support the following properties:
- id: String – an optional unique identifier for the document. If no value is provided, one will be generated as part of the request. The value must be unique for the index
- contentType: String – the optional MIME type for the content being uploaded. If no value is provided, the system will attempt to determine the appropriate value from the file’s “extension”. If the content type is not given and cannot be determined, then the system will assume a type of “text/plain”.
- metadata: Object – an optional collection of name/value pairs associated with the document. Some common keys are:
o uri: String – a URI that can be used to access the document. Useful when providing citations to the user.
The other properties depend on how the content is being provided. The type of the entry is determined as follows (the first type that applies is chosen). If the entry has the content property, it is embedded. If the entry has the uri property, it is remote. If the entry has the resource property, it is a resource. Otherwise, it is expected to be uploaded via the TUS procotol.
-
- Embedded – the contents are directly embedded in the request. The expected properties are:
- content: String – the document contents. For textual documents this will be the actual text. For binary documents it will be a Base64 encoded version of the document.
- fileName: String – optional name of the file from which the content came. The property will be used to determine the content type if none is provided and will be added to the entry’s metadata.</li?
- uri: String – an optional URI that can be used to access the document. This value is also used to determine the content type, if necessary. It will be added to the entry’s metadata.
- Remote – the contents are read using a publicly accessible URI. The expected properties are:
- uri: String – a URI that can be used to access the document. This value is also used to determine the content type, if necessary.
- Vantiq Resource – the contents are copied from an existing Vantiq resource (one of documents, images, or videos). The content type is taken from the referenced resource. The URI used to access the resource’s contents will be added to the metadata using the uri key. The expected properties are:
- resource: ResourceReference – a resource reference for the resource to be indexed.
- fileName – ignored if provided
- TUS Upload – the contents will be uploaded separately via the TUS protocol. The expected properties are:
- fileName: String – optional name of the file from which the content came. The property will be used to determine the content type if none is provided and will be added to the entry’s metadata.
- Embedded – the contents are directly embedded in the request. The expected properties are:
This operation can be used to both add new documents to an index or to update a document that is already part of the index. In the latter case, the id property must be provided and must refer to the document being replaced. Otherwise, the operation will be treated as an addition.
Processing Zip Files
When adding an entry that contains/references a zip file, the server will first “unzip” the file and then process each file it contains individually. The index itself will have only one entry, no matter how many files the zip contains. However, it is often useful to attach slightly different metadata to each file in the zip, even though they are processed together. To support this the metadata associated with a zip file entry is expected to have a slightly more structured form. At the root it is expected to have two properties: global and perFile. All properties found under global will be applied to every file in the zip (though they can be overridden). The properties under perFile are expected to correspond to directories and/or files found in the zip and refer to a sub-object. The sub-objects associated with a file will apply their properties to the metadata for that file (overriding any set from a previous “level”). The sub-objects associated with a directory act as a new root and are expected to have the properties global and perFile. For example, let’s say a zip file contains the following contents (shown as a directory structure):
index.md
api.md
sources/
sms.md
remote.md
The following is a legal metadata document:
{
“global”: {“category”: “plain”, “zipFile”: “indexContent.zip”},
“perFile”: {
“index.md”: {“title”: “Introduction”},
“sources”: {
“global”: {“category”: “sources”},
“perFile”: {“sms.md”: {“title”: “SMS Source”}}
}
}}
The final metadata properties for each file would be:
-
-
- index.md
- category – plain
- zipFile – index.Context.zip
- title – Introduction
- api.md
- category – plain
- zipFile – index.Context.zip
- sms.md
- category – sources
- zipFile – index.Context.zip
- title – SMS Source
- remote.md
- index.md
-
Remove Entries
Specifies one or more documents to be removed from the index. The request requires an array of String values, each of which should match the id of a document contained in the index. Each of the identified documents will be removed from the index.
Clear Index
Removes all documents from the index, resulting in an index that is empty.
Search Index
Performs a similarity search against the index using a provided input value. The request expects the following parameters:
-
- queryValue – the value used to perform the similarity search.
- filter – an optional query document used to constrain the search to documents with matching metadata. The logical operators supported by the filter are dependent on the underlying Vector DB (and TBD).
- props – an optional list of metadata property names to include or exclude from the results. By default, the given properties will be included, unless the property name begins with a minus sign (“-“). By default, the search results will include all metadata properties.
- limit – an optional number of results to return from the search. The default value is 5.
To perform the search the index will use its associated LLM to generate an embedding for the query value. Then it will perform a (possibly filtered) similarity search and return the results as an array of Objects containing the following properties:
- score – the similarity score (based on the search algorithm being used).
- metadata – the metadata values associated with the matched item (possibly adjusted based on the provided props value).
Import, Export and Deployment
Each Semantic Index instance represents both the metadata that describes the index and its configuration and access to the content that has been used to populate the index. Managing import, export, and deployment of the metadata is straightforward. The index content, on the other hand, presents some challenges. In a production scenario, indexes may be quite large (we had initial conversations with customers who plan to load millions of documents) and simply extracting and/or transferring their content on every import or deployment is unlikely to work well. What makes more sense is to think about manipulating the content in bulk, at the database level. This leads us to the following proposal.
Import, export, and deployment of the semantic index resource instances will only deal with the metadata. So, if you export a semantic index from one namespace and import it into another, it will be empty on import. The same will be true when you deploy a semantic index across namespaces. At this point you have 2 options. You can choose to reload the index with new content (possibly the same as was used, possibly different) or you can use the Dump and Load operations to transfer the data from the source index to target index.
Dump
The dump operation produces a ZIP file containing the current contents of the target index. The exact format/contents of this are TBD, but hopefully we can leverage the backup/restore format of our chosen Vector DB to help with this.
Load
Load accepts the file created by dump and re-initializes the index to have exactly that content. Any existing data in the index will be removed prior to the load.
Performing Semantic Searches
Once we have a semantic index, we can now perform semantic searches against it. As shown above, this involves:
- Accepting a query from the user/application.
- Creating an embedding for that query.
- Using the embedding to perform a similarity search against the sematic index.
- Feeding the results of that search, plus the original query, to a “generative” LLM so that it can synthesize a response.
If we want to support a “conversational” style of interaction, then we also need the ability to pose “follow up” queries and include previous queries and responses in the data sent to the LLM (this is sometimes referred to as “memory”).
What we have here is a series of interactions between the semantic index and LLM resources. Rather than force the developer to manage all of this themselves, we propose to encapsulate these interactions in a “Semantic Search” service. This will be a stateful service which manages multiple semantic searches for the developer. To initiate a search, the developer will first establish a new search “session”, specifying the index to search and the LLM to use when generating responses. Both resources must exist and the referenced LLM must be a “generative” model. Once a search session is established, it can be used to process queries as described above. Each of these interactions involves providing the query text and receiving the answer text from the service. Optionally, the developer can provide a “conversation id” which is simply a string value. Requests with the same id value are part of the same “conversation” which means that the LLM will be provided with a summary of the conversation to that point, in addition to the query and similarity search results. The source and contents of the query will vary depending on the application. A Q&A or “help” system might accept them directly from the user. Other applications might construct them by combining user input with other context obtained via Vantiq types or from another service. Developers can use templates to assist in this process.
Clients are free to establish multiple, simultaneous, search sessions and to specify multiple “conversations” within each session. The service will be accessible through all the standard bindings (REST, VAIL, and WS).
Semantic Search Service API
The service’s API consists of the following procedures:
- answerQuestion(indexName String Required, question String Required, qaLLM String, conversationId String): Object – answer a question using the context contained in the specified semantic index. The answer will be synthesized by the specified generative LLM (if provided). If no qaLLM value is provided, then it will use the index’s default Q&A LLM (if there is one). An optional conversationId can be provided to associate the question with a previously established “conversation”. The result object will have the following properties:
- answer: String – the answer synthesized by the generative LLM.
- metadata: Object Array – an array of metadata objects derived from the index entries used to synthesize the answer. The exact metadata present is determined by the index entries.
- startConversation(initialState ChatMessage Array, conversationId String): String – start a Q&A “conversation” with the given initialState. Once established, the conversation will keep track of any question/answer pairs that occur as part of the conversation (indicated by passing the conversation’s id to the answerQuestion procedure). The initialState parameter accepts an Array of Objects with the following properties:
- type: String – the type of message being provided. Legal values are human, ai, system, and chat.
- content: String – the message content.
The return value is an opaque String referred to as a “conversation id”. This value can be provided by the caller (useful when associating the conversation with an existing resource such as a collaboration). Otherwise, it will be generated by the system.
- getConversationState(conversationId String Required): ChatMessage Array – returns the current state of the specified conversation.
- endConversation(conversationId String Required) – terminates the conversation with the given id. To help with resource management, conversations will automatically expire and be closed after 30 minutes of inactivity.
Modeling LLMs
Large Language Models (LLMs) are not a single, uniform entity which can perform any task. Rather, there are lots of different models, designed to provide many different capabilities. How and when to use each depends on what you are trying to accomplish. As we’ve seen, semantic search requires interaction with an “embedding” LLM to both create and query a semantic index and a “generative” model to synthesize responses. Other Gen AI capabilities may require still other types of models. To help us model these we propose the addition of the LLM (llms) resource. Instances of this resource represent a specific model (e.g. “gpt-3.5-turbo”), with specific capabilities and the information needed to interact with the model.
LLM Resource
The llms resource is a Vantiq system resource with the following properties:
- name: String – a unique identifier for the resource instances which must conform to standard Vantiq resource name constraints. The name can include a package name using our standard format.
- type: String – an enumerated value describing the function performed by the model. Currently legal values are embedding and generative.
- modelName: String – the name of the model to be run (e.g. “gpt-3.5-turbo” or “gpt-3.5-turbo-310”).
- description: String – an optional, human readable description of the model.
- vectorSize: Integer – the size of the vectors produced by the model. Required if the type is “embedding” and otherwise ignored.
- distanceFunction: String – the distance function to use when comparing vectors produced by
- config: Object – the (optional) configuration properties needed to initialize/connect to the model.
The resource supports the standard CRUD operations. The optional config property contains any additional information (beyond the name of the model) necessary to issue requests to the LLM. The configuration may reference values from Vantiq secrets using our standard @secret() syntax for either keys or values. For LLMs accessed via a REST API this configuration will typically contain a vendor specific API key. To help abstract this a bit and avoid the user having to know what property name is expected, we will support the following Vantiq specific key:
- apiKeySecret: String – the name of a secrets resource containing the API key used to access the remote service. This will be mapped to the underlying vendor specific configuration property based on the model selected.
Additional properties may be supported, depending on the underlying model implementation. Those will be documented on an as needed basis.
Import, Export and Deployment
The LLM resource is purely descriptive and therefore supports standard import, export, and deployment.
External Dependencies
Semantic Index UI/UX
The primary external dependency for this project is the development of a UX (and associated UI) relating to the creation and management of semantic indexes. Users will need to be able to see what indexes exist, what documents each index contains, create new indexes, load documents into an index (both from inside and outside Vantiq), and remove documents from an index. The process of loading a document is likely to be lengthy and is also likely to be implemented asynchronously to separate the process of uploading the data from the creation of embeddings and updates to the Vector DB. Users will need a way to understand the state of each document in the context of the index.
Future Considerations
Currently the Vector DB is an embedded component used to implement the semantic index resource. In the future it may make sense to model this explicitly and allow an index instance to reference the database that it wants to use.
Implementation Notes
Vector DB
After looking at a few different Vector DB options (there are lots), we decided to start with Qdrant. It is OSS, supports replication (in the OSS version) and gets generally good grades wrt scalability. Another option would be to use the “pgvector” add-on for PostgresSQL. This is attractive since we already use Postgres for storage of Keycloak data. However, there are some concerns about its performance at scale. But this decision is very much subject to change as we gain more experience.
Use of Python/LangChain
We are currently planning to base most of our Gen AI implementations on the LangChain LLM framework. The framework covers all the major capabilities needed for an LLM application and is also able to leverage supporting Python libraries which are currently far ahead of where the Java/JVM world is in this area. For example, LangChain leverages the unstructured library to support processing and encoding of a wide variety of document types (PDF, Markdown, Email, HTML, Word, …). There simply isn’t anything comparable on the Java side (at least not as OSS). LangChain also embodies significant expertise in building LLM enabled applications, such as how to craft prompts to solve commonly occurring problems. We believe that access to this expertise outweighs the cost of integrating with a Python based solution.