Developer How To Series
October 2024
Streaming AI Output
AI can be a bit slow.
Vantiq developers are used to writing application systems expecting tens of thousands of events a second, with the event processing about that fast, too. But large language model responses, depending on the complexity of the problem presented to it, can take several seconds just to answer one query.
Waiting for the model to return its full response, especially during a real-time conversation, will feel stilted with the awkward lags while the processing finishes.
Enter response streaming.
Several large language models already support streaming their responses, rather than waiting for the full, refined response to complete.
The Generative AI Builder supports response streaming as procedure output. To accomplish this, set the Return Type in the Properties settings to “Sequence”:
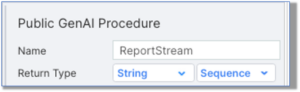
But wait, you’re not done yet. The entity that calls the procedure must be prepared to get the incremental response, too. What are those entities and how do they anticipate getting streamed returns?
From VAIL EXECUTE: To call a streamed GenAI Procedure programmatically in VAIL, use the EXECUTE statement and attach a block of code for the processing, e.g:
PROCEDURE getMyAnswer(subject String, wordCount Integer)
var count = 0
var reportTotal = “”
EXECUTE z.z.StreamSvc.ReportStream({“subject” : subject,”wordCount” : wordCount}) as myChunk
count++
}
log.info(count)
The ReportStream GenAI procedure is tasked with creating a “high school worthy” report of the subject matter and word count supplied. The “count” referenced in the execution block is to count the number of chunks created during the streamed response. Also in the execution block, we’re replacing any “e’s” found in the chunk with “+++”. Let’s try running the getMyAnswer procedure now:
The logged value was: 708, which is the number of tokens streamed in the creation of a 500-word essay on cats.
Perhaps this isn’t the most practical of examples, but the point is that the VAIL code could get to work on each token as it streamed in, and didn’t have to wait for the full response before processing the substitutions.
From Built-in Service Procedures: Vantiq’s io.vantiq.ai.LLM and io.vantiq.ai.SemanticSearch Services each include procedures to query a LLM and return a streamed response. Here’s an example from the LLM Service:
PROCEDURE LLMAnswer(subject String, wordCount Integer)
var count = 0
var reportTotal = “”
var query = “Please give me a ” + wordCount + “word essay about ” + subject
for (i in io.vantiq.ai.LLM.submitPromptAsSequence(“z.z.GPT4.0”, query)){
count++
}
log.info(count)
Running the procedure and entering “nostrils” and “500” yielded a log message of “706.”
In other words, the behavior is exactly the same as if we’d run the EXECUTE command above. The only caveat is that in order to process the tokens as they come through, we must make the procedure call part of an iteration loop.
From a Client: There are actually a couple of ways to go about using streamed returns from a Client:
- Using a Conversation Widget: Use of this widget in a Client to retrieve streamed LLM output is about as easy as connecting a garden hose to the spigot:
- First, create your GenAI procedure. Be sure to include a promptTemplate that utilizes what the Human will have to say. Example:

- Configure the Conversation widget to call the GenAI procedure:
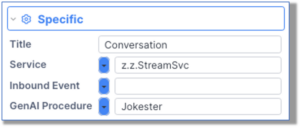
The response in the widget will come in “chunks”, followed by “…” so the reader knows more is coming:

Shortly thereafter, the rest of the output will connect where the previous left off. The convenience of course is that instead of waiting for the whole response, the Conversation widget user can begin reading from the first returned chunk.
- Programmatically from a Client: Vantiq supplies built-in executeStreamed and executeStreamedPublic functions to facilitate calling streaming GenAI procedures and receiving chunks. Here’s an example:
client.executeStreamed(args,“z.z.StreamSvc.Jokester”,
function(results)
{
client.getWidget(“JokeStory”).boundValue = JSON.stringify(results).replace(/[\”,\\]/g,”);
},
function(results)
{
client.getWidget(“JokeStory”).boundValue = JSON.stringify(results).replace(/[\”,\\]/g,”);
});
This call results in a MultilineInput widget getting output like this:

Questions?
–>Yeah, why two functions to display the results?
So glad you asked, Mr. Strawman! The top function runs for the completed execution of the procedure, and the one below it for the “chunks in progress.” To see all the chunks as they are returned, both need to display in the widget.
–>Ok, and why are you doing a string replace operation to remove quotes, back-slashes, and commas?
Ah, about that. Without the string replace, the output comes out like token-sized chunk output, but in larger actual chunks. (500 words usually resulted in three chunks.) And it’s harder to read:
RESULT: {“data”:[“”,”Once”,” upon”,” a”,” time”,” in”,” the”,” quaint”,” village”,” of”,” Wh”,”isk”,”er”,”field”,”,”,” there”,” was”,” a”,” feline”,” phenomenon”,” that”,” had”,” the”,” entire”,” town”,” in”,” a”,” tiz”,”zy”,”.”,” It”,” all”,” started”,” when”,” Mr”,”.”,” Wh” < much more redacted >
From a REST call: But of course we can call streamed-output GenAI procedures via a HTTPS POST just like we would any other procedure, but with a URL parameter stream set to true. Example:
curl –location ‘https://dev.vantiq.com/api/v1/resources/procedures/z.z.StreamSvc.Jokester?stream=true’ . . .,
So, why would we need GenAI Procedures to return sequences?
Ah, Ms. Strawwoman, you really are incisive! Using streamed returns from a GenAI procedure provides advantages in two main categories of use. These are:
- When the application can start processing the response without having to wait for the whole to return first
- When interacting with humans
You saw exactly these two types of applications. Our first example counted each element of the stream without waiting for the whole stream to complete. And as we saw with the Conversation widget example, human-ai interactions are much more natural when the large language model response doesn’t lag (as much) and presents a beginning, middle and end just like our own way of speaking.
Conclusion: Streaming is cool! Consider using Sequence output when:
- the GenAI procedure will be interacting in real-time with a human, or
- what comes back can be processed efficiently in chunks
Attachments:
You must be
logged in to view attached files.

Developer How To Series
October 2024
Streaming AI Output
AI can be a bit slow.
Vantiq developers are used to writing application systems expecting tens of thousands of events a second, with the event processing about that fast, too. But large language model responses, depending on the complexity of the problem presented to it, can take several seconds just to answer one query.
Waiting for the model to return its full response, especially during a real-time conversation, will feel stilted with the awkward lags while the processing finishes.
Enter response streaming.
Several large language models already support streaming their responses, rather than waiting for the full, refined response to complete.
The Generative AI Builder supports response streaming as procedure output. To accomplish this, set the Return Type in the Properties settings to “Sequence”:
But wait, you’re not done yet. The entity that calls the procedure must be prepared to get the incremental response, too. What are those entities and how do they anticipate getting streamed returns?
From VAIL EXECUTE: To call a streamed GenAI Procedure programmatically in VAIL, use the EXECUTE statement and attach a block of code for the processing, e.g:
The ReportStream GenAI procedure is tasked with creating a “high school worthy” report of the subject matter and word count supplied. The “count” referenced in the execution block is to count the number of chunks created during the streamed response. Also in the execution block, we’re replacing any “e’s” found in the chunk with “+++”. Let’s try running the getMyAnswer procedure now:
The logged value was: 708, which is the number of tokens streamed in the creation of a 500-word essay on cats.
Perhaps this isn’t the most practical of examples, but the point is that the VAIL code could get to work on each token as it streamed in, and didn’t have to wait for the full response before processing the substitutions.
From Built-in Service Procedures: Vantiq’s io.vantiq.ai.LLM and io.vantiq.ai.SemanticSearch Services each include procedures to query a LLM and return a streamed response. Here’s an example from the LLM Service:
Running the procedure and entering “nostrils” and “500” yielded a log message of “706.”
In other words, the behavior is exactly the same as if we’d run the EXECUTE command above. The only caveat is that in order to process the tokens as they come through, we must make the procedure call part of an iteration loop.
From a Client: There are actually a couple of ways to go about using streamed returns from a Client:
The response in the widget will come in “chunks”, followed by “…” so the reader knows more is coming:
Shortly thereafter, the rest of the output will connect where the previous left off. The convenience of course is that instead of waiting for the whole response, the Conversation widget user can begin reading from the first returned chunk.
This call results in a MultilineInput widget getting output like this:
Questions?
–>Yeah, why two functions to display the results?
So glad you asked, Mr. Strawman! The top function runs for the completed execution of the procedure, and the one below it for the “chunks in progress.” To see all the chunks as they are returned, both need to display in the widget.
–>Ok, and why are you doing a string replace operation to remove quotes, back-slashes, and commas?
Ah, about that. Without the string replace, the output comes out like token-sized chunk output, but in larger actual chunks. (500 words usually resulted in three chunks.) And it’s harder to read:
RESULT: {“data”:[“”,”Once”,” upon”,” a”,” time”,” in”,” the”,” quaint”,” village”,” of”,” Wh”,”isk”,”er”,”field”,”,”,” there”,” was”,” a”,” feline”,” phenomenon”,” that”,” had”,” the”,” entire”,” town”,” in”,” a”,” tiz”,”zy”,”.”,” It”,” all”,” started”,” when”,” Mr”,”.”,” Wh” < much more redacted >
From a REST call: But of course we can call streamed-output GenAI procedures via a HTTPS POST just like we would any other procedure, but with a URL parameter stream set to true. Example:
So, why would we need GenAI Procedures to return sequences?
Ah, Ms. Strawwoman, you really are incisive! Using streamed returns from a GenAI procedure provides advantages in two main categories of use. These are:
You saw exactly these two types of applications. Our first example counted each element of the stream without waiting for the whole stream to complete. And as we saw with the Conversation widget example, human-ai interactions are much more natural when the large language model response doesn’t lag (as much) and presents a beginning, middle and end just like our own way of speaking.
Conclusion: Streaming is cool! Consider using Sequence output when:
Attachments:
You must be logged in to view attached files.